

Windows Server 2012 wprowadza nową funkcję Dane Deduplikacja (Deduplikacja danych). Co to jest deduplikacja? Deduplikacja danych ogólnie jest to procedura znajdowania i usuwania duplikatów danych na nośniku pamięci bez narażania integralności informacji. Celem duplikacji jest przechowywanie informacji w małych blokach (32-128 Kb), identyfikowanie ich (duplikaty bloków) i zapisywanie tylko jednej kopii dla każdego bloku, i zastępowanie duplikatów blokami linkami do pojedynczej kopii.
Wcześniej konieczne było używanie produktów innych firm do organizowania deduplikacji (istnieją zarówno sprzętowe rozwiązania deduplikacji na poziomie macierzy dyskowych, jak i oprogramowanie na poziomie plików). Koszt takich rozwiązań był dość wysoki, ponieważ są one skierowane przede wszystkim do zamożnych klientów korporacyjnych. Teraz ta funkcja jest całkowicie bezpłatna dla wszystkich użytkowników systemu Windows Server 2012.
Istnieje mały hack, który pozwala włączyć deduplikację w systemach operacyjnych klienta (Windows 8 i Windows 8.1). Szczegóły w artykule: Jak włączyć deduplikację danych w systemie Windows 8.1W systemie Windows Server 2012 deduplikacja jest implementowana jako dwa składniki:
- Filtruj sterownik, który kontroluje funkcje wejścia / wyjścia
- Usługi deduplikacji - kontroluje trzy operacje („Odśmiecanie”, „Optymalizacja” i „Czyszczenie”).
Te elementy są odpowiedzialne za wyszukiwanie pasujących danych, organizowanie ich przechowywania w liczbie pojedynczej i prawidłowe zapewnianie do nich dostępu.
Wcześniej deduplikację w produktach Microsoft wykryto na serwerze pocztowym Exchange 200/2003/2007 - w komponencie Pamięć pojedynczej instancji (tylko jedna kopia wiadomości jest przechowywana na serwerze w skrzynce pocztowej jednego z adresatów, a reszta adresatów otrzymuje tylko link do niego).
Deduplikacja danych w systemie Windows Server 2012 działa w tle i domyślnie rozpoczyna się co godzinę. Proces rozpoczyna się, gdy obciążenie serwera jest niskie i nie zmniejsza ogólnej wydajności serwera. Domyślnie pliki, które nie były dostępne przez ponad 30 dni, są deduplikowane. Ponadto procedura nie jest wykonywana dla następujących typów plików: aac, aif, aiff, asf, asx, au, avi, flac, jpeg, m3u, środkowy, midi, mov, mp1, mp2, mp3, MP4, mpa, mpe, MPEG, mpeg2, MPEG3, mpg, ogg, qt, qtw, baran, rm, rmi, rmvb, snd, swf, vob, WAV, wosk, wma, wmv, wvx, accdb, accde, accdr, accdt, docm, docx, dotm, dotx, pptm, potm, potx, ppam, ppsx, pptx, sldx, sldm, thmx, xlsx, xlsm, xltx, xltm, xlsb, Xlam, xll, as, łuk, arj, bhx, b2, kabina, gz, gzip, hpk, hqx, słoik, lha, lzh, lzx, pak, pit, rar, morze, usiądź, sqz, tgz, uu, uue, z, zip, zoo.
Funkcja zarządzania deduplikacją jest dostępna z GUI i PowerShell. Rozważ obie opcje.
Windows Server 2012 Interfejs użytkownika do deduplikacji danych
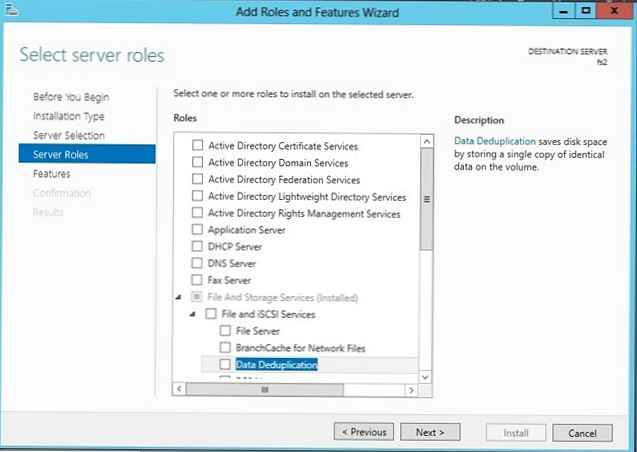
Aby włączyć deduplikację danych, musisz zainstalować komponent Dane Deduplikacja role Usługi plików i przechowywania. Możesz to zrobić z konsoli Serwer Manahger.
Po zakończeniu instalacji komponentu otwórz Menedżera serwera -> Serwery plików i pamięci -> Woluminy -> konsola i kliknij prawym przyciskiem myszy sekcję, dla której chcesz włączyć deduplikację, i wybierz Skonfiguruj deduplikację danych.
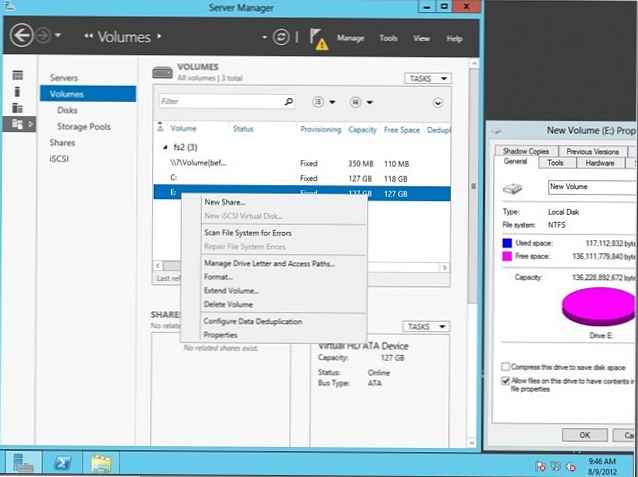
W następnym oknie zaznacz „Włącz deduplikację danych”. Tutaj możesz określić katalogi, które nie muszą być deduplikowane, oraz ustawienia harmonogramu deduplikacji.
Bieżący poziom deduplikacji zostanie wyświetlony w kolumnie. Deduplikacja Oceń (zaktualizowany za kilka godzin).
Aby przeanalizować wykorzystanie miejsca na dysku i możliwe oszczędności wynikające z włączenia deduplikacji dla tego woluminu, opracowano narzędzie DDPEVAL.exe. Możesz oszacować, ile miejsca na dysku możesz zaoszczędzić po włączeniu deduplikacji danych za pomocą następującego polecenia (zwróć uwagę, że w przypadku dużych woluminów może to spowodować znaczne obciążenie procesora)
c: \ windows \ system32 \ ddpeval.exe e: \
W moim przypadku oszczędności wyniosłyby około 57%.
Deduplikacja PowerShell
Proces deduplikacji można również kontrolować za pomocą programu Powershell. Aby to zrobić, zainstaluj funkcję deduplikacji danych za pomocą poleceń:
Import-Module ServerManager
Dodaj-WindowsFeature -name FS-Data-Deduplikacja
Deduplikacja modułu importu
Po włączeniu funkcji deduplikacji należy ją skonfigurować. Aby włączyć deduplikację dla dysku D: uruchom polecenie:
Enable-DedupVolume D:

Domyślnie pliki, do których nie można uzyskać dostępu (Ostatni dostęp) przez ponad 30 dni, są deduplikowane. Tę wartość można zmienić na przykład na 2 dni. Aby to zrobić, uruchom polecenie:
Set-DedupVolume D: -MinimumFileAgeDays 2
Zazwyczaj proces deduplikacji jest uruchamiany przez program planujący systemu Windows, ale można go również uruchomić ręcznie:
Start-DedupJob D: Optymalizacja typu
Bieżące statystyki można wyświetlić za pomocą polecenia:
Get-DedupStatus

Listę bieżących zadań można znaleźć za pomocą polecenia:
Get-DedupJob
Wszystkie wyniki dla woluminu można wyświetlić za pomocą polecenia PoSH:
Get-DedupMetadata -Volume D:
I na koniec możesz całkowicie anulować deduplikację woluminu za pomocą polecenia:
Start-DedupJob -Volume D: -Type Unoptimization
Poniższy zrzut ekranu pokazuje, że po włączeniu deduplikacji na dysku E: (do testu umieściłem na nim 4 takie same ISO w systemie Windows 8), rozmiar używanego miejsca na dysku zmniejszył się z 12 GB do 3 GB. 
Najlepsze praktyki korzystania z deduplikacji danych w systemie Windows Server 2012
Microsoft opublikował następujące wyniki badania skuteczności powielania różnych typów danych.
| Typy danych | Możliwe oszczędności miejsca |
| Dane ogólne | 50–60% |
| Dokumenty | 30–50% |
| Biblioteka aplikacji | 70–80% |
| Biblioteka VHD (X) | 80–95% |
Najważniejsze funkcje deduplikacji danych w systemie Windows Server 2012:
- Działa tylko na woluminach NTFS i nie obsługuje systemu plików ReFS.
- Nieobsługiwany dla woluminów rozruchowych i systemowych
- Nie działa ze skompresowanymi i zaszyfrowanymi plikami NTFS
- Obsługuje buforowanie i BITS
- Nie obsługuje plików mniejszych niż 32 KB
- Nie skonfigurowano za pomocą zasad grupy
- Nie obsługuje udostępnionych woluminów klastra
- Deduplikacja - proces nie jest natychmiastowy i zajmuje trochę czasu



{kind=link}