


W tym artykule zainstalujemy DBMS PostgreSQL 11 w systemie Linux CentOS 7 wykonamy podstawową konfigurację serwera i DBMS, uwzględnimy główne parametry pliku konfiguracyjnego, a także sposoby dostrajania wydajności. PostgreSQL to popularny darmowy system zarządzania obiektowo-relacyjnymi bazami danych. Chociaż nie jest tak rozpowszechniony jak MySQL / MariDB, jest najbardziej profesjonalny.
Mocne strony PostgreSQL:
- Pełna zgodność ze standardami SQL;
- Wysoka wydajność dzięki wielowymiarowemu zarządzaniu współbieżnością (MVCC);
- Skalowalność (szeroko stosowana w środowiskach o dużym obciążeniu);
- Obsługa wielu języków programowania;
- Niezawodne mechanizmy transakcji i replikacji;
- Obsługa danych JSON.
Treść
- Zainstaluj PostgreSQL na CentOS / RHEL
- Połącz się z PostgreSQL, utwórz bazę danych, użytkownik
- Podstawowe opcje pliku konfiguracyjnego PostgreSQL
- Tworzenie kopii zapasowej i przywracanie bazy danych w PostgreSQL
- Optymalizacja i strojenie PostgreSQL
Zainstaluj PostgreSQL na CentOS / RHEL
Chociaż PostgreSQL może być zainstalowany z podstawowego repozytorium CentOS, będziemy instalować repozytorium od programistów, ponieważ zawsze ma ono najnowszą wersję pakietu.
Pierwszym krokiem jest instalacja repozytorium PosgreSQL (obecnie jest instalowany w następujący sposób):
mniam zainstalować -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm
To repozytorium zawiera zarówno najnowsze wersje PostgreSQL, jak i starsze wersje. Informacje o repozytorium są następujące:
Zainstaluj najnowszą dostępną wersję (PostrgeSQL 11), używając yum.
mniam zainstalować postgresql11-server -y
Podczas instalacji instalowany jest sam serwer PostgreSQL i niezbędne biblioteki:
Instalowanie: libicu-50.2-3.el7.x86_64 1/4 Instalowanie: postgresql11-libs-11.5-1PGDG.rhel7.x86_64 2/4 Instalowanie: postgresql11-11.5-1PGDG.rhel7.x86_64 3/4 Instalowanie: postgresql11-server- 11.5-1PGDG.rhel7.x86_64 4/4
Po zainstalowaniu pakietów musisz zainicjować bazę danych:
/ usr / pgsql-11 / bin / postgresql-11-setup initdb
Ponadto natychmiast dodaj serwer bazy danych do uruchamiania i uruchom go:
systemctl włącza postgresql-11
systemctl start postgresql-11
Aby upewnić się, że serwer został uruchomiony i że nie ma żadnych problemów, sprawdź jego status:
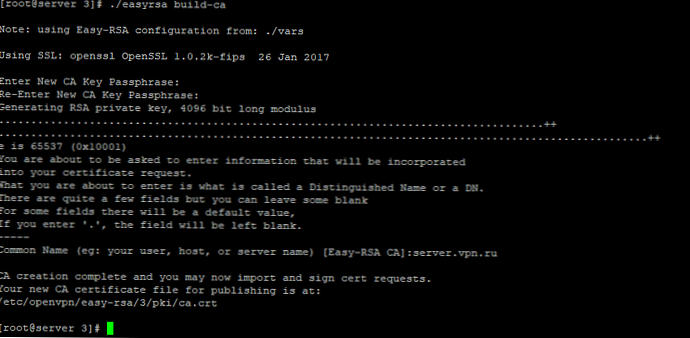
[root @ server ~] # systemctl status postgresql-11
● postgresql-11.service - Serwer bazy danych PostgreSQL 11 Załadowany: załadowany (/usr/lib/systemd/system/postgresql-11.service; włączony; preset dostawcy: wyłączony) Aktywny: aktywny (uruchomiony) od środy 2019-09-18 13:01:56 +06; 26s temu Dokumenty: https://www.postgresql.org/docs/11/static/ Proces: 6614 ExecStartPre = / usr / pgsql-11 / bin / postgresql-11-check-db-dir $ PGDATA (code = zakończony, status = 0 / SUKCES) Główny PID: 6619 (postmaster) Grupa C: /system.slice/postgresql-11.service ├─6619 / usr / pgsql-11 / bin / postmaster -D / var / lib / pgsql / 11 / data / ├─6621 postgres: logger ├─6623 postgres: checkpointer ├─6624 postgres: pisarz w tle ├─6625 postgres: walwriter ├─6626 postgres: autovacuum launcher ├─6627 postgres: kolektor statystyk └─6628 postgres: logiczne uruchamianie replikacji 18 września 13:01:56 server.1.com systemd [1]: Uruchamianie serwera bazy danych PostgreSQL 11 ... 18 września 13:01:56 server.1.com postmaster [6619]: 18.09.2019 13: 01: 56.399 +06 [6619] LOG: nasłuchuje na adresie IPv6 „:: 1”, port 5432 18 września 13:01:56 server.1.com postmaster [6619]: 18.09.2019 13: 01: 56.399 +06 [6619 ] LOG: nasłuchuje na adresie IPv4 „127.0.0.1”, port 5432 18 września 18 13:01:56 server.1.com postmaster [6619]: 2019-09-18 13: 01: 56.401 +06 [6619] LOG: słuchanie na gnieździe Uniksa "/var/run/postgresql/.s.PGSQL.5432" 18 września 13:01:56 server.1.com postmaster [6619]: 2019-09-18 13: 01: 56.409 +06 [6619] LOG: nasłuchiwanie na gnieździe Uniksa "/tmp/.s.PGSQL.5432" 18 września 13:01:56 server.1.com postmaster [6619]: 18.09.2019 13: 01: 56.427 +06 [ 6619] LOG: przekierowanie danych wyjściowych dziennika do procesu gromadzenia danych rejestrujących 18 września 13:01:56 server.1.com postmaster [6619]: 2019-09-18 13: 01: 56.427 +06 [6619] WSKAZÓWKA: Pojawi się wynik przyszłych dzienników w katalogu „log”. 18 września 13:01:56 server.1.com systemd [1]: Uruchomiono serwer bazy danych PostgreSQL 11.
Jeśli potrzebujesz dostępu do PostgreSQL z zewnątrz, musisz otworzyć port TCP / 5432 w standardowej zaporze ogniowej w Centos 7:
# firewall-cmd --get-active-zone
interfejsy publiczne: eth0
# firewall-cmd --zone = public --add-port = 5432 / tcp --permanent
# firewall-cmd --reload
Lub przez iptables:
# iptables-A WEJŚCIE -m stan - stan NOWY -m tcp -p tcp --port 5432 -j AKCEPTUJ
# service iptables restart
Jeśli SELinux jest włączony, wykonaj:
setsebool -P httpd_can_network_connect_db 1
Połącz się z PostgreSQL, utwórz bazę danych, użytkownik
Domyślnie podczas instalacji PostgreSQL w systemie jest jeden użytkownik - postgres.
Nie polecam używania go do pracy z bazami danych, lepiej jest utworzyć użytkowników dla każdej bazy danych osobno.
Aby połączyć się z serwerem Postgres, musisz wpisać polecenie:
[root @ server /] # sudo -u postgres psql
psql (11.5) Wpisz „help”, aby uzyskać pomoc.
postgres = #
Konsola PostgreSQL została otwarta. Pokażmy kilka prostych przykładów sterowania PostgreSQL z konsoli psql.
Ponieważ każdy użytkownik systemu może zalogować się do postrgesql, najpierw musisz zmienić hasło do postgres.
ZMIEŃ ROLĘ postgres Z HASŁEM „super_str0ng_pa $$ word”;
Natychmiast utwórz nową bazę danych, użytkownik i daj mu pełne prawa do tej bazy danych:
postgres = # UTWÓRZ BAZA DANYCH mydbtest;
postgres = # UTWÓRZ UŻYTKOWNIKA mydbuser Z hasłem „123456789”;
postgres = # PRZYZNAJ WSZYSTKIE UPRAWNIENIA DO BAZY DANYCH mydbtest TO mydbuser;
Połącz z bazą danych:
postgres = # \ c nazwa bazy danych
Listy tabel:
postgres = # \ dt
Lista zapytań do bazy danych:
postgres = # wybierz * z pg_stat_activity gdzie datname = "dbname"
Zresetuj wszystkie połączenia z bazą danych:
postgres = # wybierz pg_terminate_backend (pid) z pg_stat_activity gdzie dataname = 'dbname'
Informacje o bieżącej sesji można uzyskać w następujący sposób:
postgres = # \ conninfo
Aby ukończyć konsolę psql, uruchom:
postgres = # \ q
Jak już zauważyłeś, składnia nie różni się od tej samej MariaDB lub MySQL, a zatem nie będziemy rozwodzić się nad poleceniami tego samego typu.
Należy pamiętać, że w celu wygodniejszego zarządzania bazami danych PostgreSQL z interfejsu sieciowego zaleca się użycie pgAdmin4 (napisanego w Pythonie i Javascript / jQuery). Jest to odpowiednik zwykłych programistów stron internetowych PhpMyAdmin.
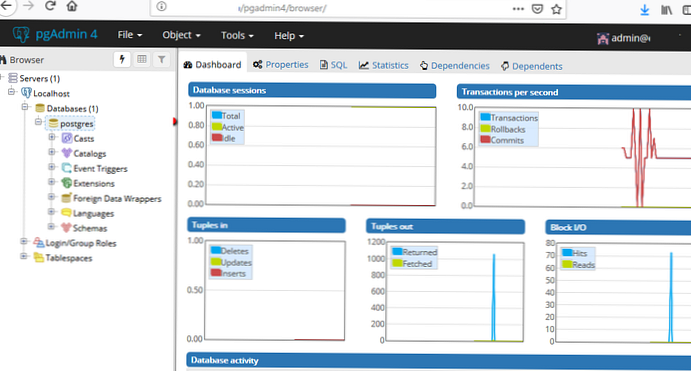
Podstawowe opcje pliku konfiguracyjnego PostgreSQL
Pliki konfiguracyjne Postgresql znajdują się w katalogu / var / lib / pgsql / 11 / data:
- postgresql.conf - Sam plik konfiguracyjny postgresql
- pg_hba.conf - plik z ustawieniami dostępu. W tym pliku możesz ustawić różne ograniczenia dla użytkowników, ustawić zasady łączenia się z bazą danych;
- pg_ident.conf - plik ten służy do identyfikacji klientów za pomocą protokołu ident.
Aby uniemożliwić lokalnym użytkownikom logowanie się do Postgres bez autoryzacji, określ w pliku pg_hba.conf:
lokalny wszystkie wszystkie hosty md5 wszystkie wszystkie 127.0.0.1/32 md5
Rozważ najważniejsze parametry w pliku konfiguracyjnym postgresql.conf:
- adres_słuchiwania - wskazuje, które adresy IP serwer akceptuje połączenia klientów. Domyślnie określony jest localhost, co oznacza, że możliwe jest tylko połączenie lokalne. Aby to zrobić we wszystkich interfejsach IPv4, podaj 0.0.0.0
- max_connections - podobnie jak w innych DBMS, jest to maksymalna liczba jednoczesnych połączeń z serwerem bazy danych;
- temp_buffers - maksymalny rozmiar buforów tymczasowych;
- shared_buffers - Ilość pamięci współdzielonej używanej przez serwer bazy danych. Zazwyczaj jest ustawiony na 25% pamięci zainstalowanej na serwerze;
- rozmiar_cache_wydajny - Parametr, który pomaga programistom Postgres określić ilość dostępnej pamięci do buforowania na dysk. Zazwyczaj parametr jest ustawiony na rozmiar 50–75% całkowitej pamięci RAM na serwerze;
- work_mem - ilość pamięci, która zostanie wykorzystana przez wewnętrzne operacje sortowania DBMS - ORDER BY, DISTINCT i merge;
- Maintenance_work_mem - ilość pamięci, która zostanie wykorzystana przez operacje wewnętrzne - VACUUM, CREATE INDEX i ALTER TABLE ADD THEE FOREIGN Key;
- fsync - jeśli ta opcja jest włączona, DBMS będzie czekał na zapis danych fizycznych na dysku twardym. Po włączeniu fsync łatwiej będzie przywrócić bazę danych po awarii systemu lub sprzętu. Oczywiście włączenie tego parametru znacznie zmniejsza wydajność DBMS, ale zwiększa niezawodność pamięci. Podczas wyłączania tego parametru warto wyłączyć full_page_writes;
- max_stack_depth - maksymalny rozmiar stosu (domyślnie 2 MB);
- max_fsm_pages - Za pomocą tego parametru można zarządzać wolnym miejscem na dysku na serwerze. Na przykład po usunięciu danych z tabeli zajmowane wcześniej miejsce nie jest zwalniane na dysku, ale jest oznaczane na mapie wolnego miejsca etykietą „wolne”, a następnie wykorzystywane do nowych wpisów w tabeli. Jeśli serwer aktywnie rejestruje / usuwa dane w tabelach, zwiększenie tego parametru pozytywnie wpłynie na wydajność;
- wal_buffers - ilość pamięci współdzielonej (shared_buffers), która jest używana do przechowywania danych WAL;
- wal_writer_delay - czas między okresami zapisywania WAL na dysku;
- commit_delay - opóźnienie między zapisaniem transakcji w buforze WAL a opróżnieniem jej na dysk;
- synchronous_commit - parametr określa, że wynik pomyślnego zakończenia transakcji zostanie wysłany, gdy dane WAL zostaną fizycznie zapisane na dysku.
Tworzenie kopii zapasowej i przywracanie bazy danych w PostgreSQL
Istnieje kilka sposobów tworzenia kopii zapasowej bazy danych PostgreSQL. Rozważmy najprostszą opcję..
Najpierw sprawdź, które bazy danych działają na serwerze:
postgres = # \ lista
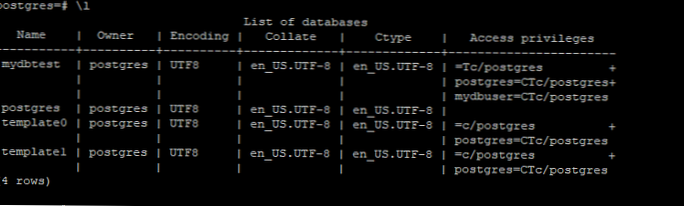
Mamy 4 bazy danych, z których 3 są systemowe (postgres i szablon).
Wcześniej utworzyliśmy bazę danych o nazwie „mydbtest”, wykorzystując jej przykład i kopię zapasową.
Jednym ze sposobów wykonania kopii zapasowej jest wykonanie jej za pomocą narzędzia pg_dump:
sudo -u postgres pg_dump mydbtest> /root/dupm.sql - wykonujemy żądanie od użytkownika postgres, określ żądaną bazę danych i ścieżkę do pliku, w którym chcesz zapisać zrzut bazy danych. System kopii zapasowych może pobrać zrzut bazy danych lub, jeśli korzystasz z serwera WWW, możesz wysłać go do magazynu w chmurze.
Aby przywrócić określony zrzut do żądanej bazy danych, możesz użyć narzędzia psql:
sudo -u postgres psql mydbtest < /root/dupm.sql
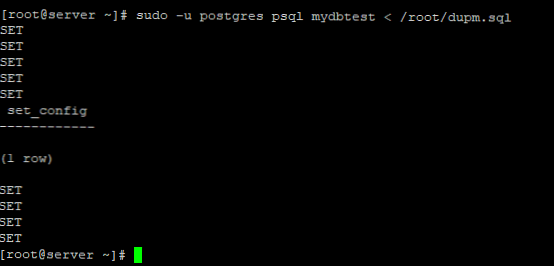
Możesz także utworzyć kopię zapasową w specjalnym formacie zrzutu i skompresowanym za pomocą gzip:
sudo -u postgres pg_dump -Fc mydbtest> /root/dumptest.sql
Taki zrzut jest przywracany za pomocą narzędzia pg_restore:
sudo -u postgres pg_restore -d mydbtest /root/dumptest.sql
Bardziej zaawansowane ustawienia można znaleźć w pomocy dla tych narzędzi:
człowiek psql
człowiek pg_dump
człowiek pg_restore
Optymalizacja i strojenie PostgreSQL
W poprzednim artykule o MariaDB pokazaliśmy, jak parametry pliku konfiguracyjnego my.cnf można zredukować do idealnego poziomu za pomocą tunerów. W przypadku PostgreSQL istnieje, chociaż bardziej poprawne było powiedzenie takiego narzędzia, jak PgTun, ale niestety nie był on aktualizowany przez długi czas. Jednocześnie istnieje wiele usług online, za pomocą których można skonfigurować optymalną konfigurację dla PostgreSQL. Podoba mi się ta usługa pgtune.leopard.in.ua.
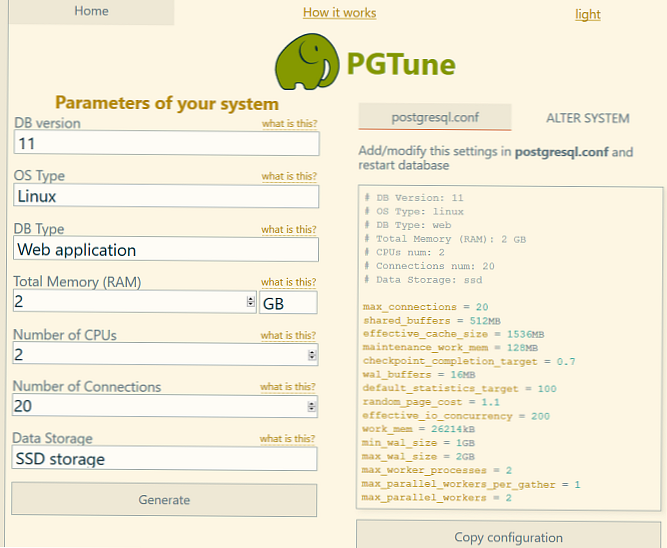
Interfejs jest bardzo prosty. Musisz określić parametry swojego serwera (profil, procesory, pamięć, rodzaj dysków) i kliknij przycisk „Generuj”. W rezultacie otrzymasz wariant pliku konfiguracyjnego postgresql.conf z zalecanymi wartościami głównych parametrów DBMS.
Na przykład dla serwera SSD VPS z 2 GB pamięci RAM i 2 procesorami zalecane są następujące ustawienia w pliku postgresql.conf w celu uruchomienia kilku witryn:
# Wersja DB: 11 # Typ systemu operacyjnego: linux # Typ bazy danych: web # Całkowita pamięć (RAM): 2 GB # Liczba procesorów: 2 # Liczba połączeń: 20 # Przechowywanie danych: ssd max_connections = 20 shared_buffers = 512 MB efektywna_waga_cache = 1536 MB Maintenance_work_mem = 128 MB cel_konkurencyjny_cel = 0,7 wal_buffers = 16 MB default_statistics_target = 100 random_page_cost = 1,1 efektywna_konkurencja = 200 work_mem = 26214kB min_wal_size = 1 GB max_wal_size = 2 GB max_worker_processes = 2 max_parallel_para
I w rzeczywistości nie jest to jedyny zasób, w czasie pisania dostępne były podobne usługi:
- Konfigurator Cybertec PostgreSQL
- Narzędzie konfiguracyjne PostgreSQL


Korzystając z tych usług, możesz szybko skonfigurować początkowe parametry DBMS dla swojego sprzętu i zadań. W przyszłości musisz polegać nie tylko na zasobach serwera, ale także analizować bazę danych jako całość, jej rozmiar, liczbę połączeń, i na tej podstawie przeprowadzić dalsze dostrajanie parametrów PostgreSQL.
{kind=link}