

Jeden z kamieni węgielnych technologii identyfikacji i bezpieczeństwa - Dynamiczna kontrola dostępu (dynamiczna kontrola dostępu) w systemie Windows Server 2012 jest funkcjonalna Infrastruktura klasyfikacji plików (FCI - infrastruktury klasyfikacji plików). FCI jest używany na serwerach plików organizacji i umożliwia tworzenie nowych właściwości i atrybuty(Właściwości klasyfikacji plików) dla klasyfikacja pliku. FCI pozwala automatycznie klasyfikować pliki zgodnie z zawartością pliku lub katalogu, w którym się znajdują; zarządzać plikami (na przykład okres, w którym możliwy jest dostęp do pliku); generuje raporty pokazujące rozkład właściwości klasyfikacji na serwerze plików. Pliki oparte na słowach kluczowych lub wzorach mogą być automatycznie klasyfikowane, na przykład jako poufne lub zawierające dane osobowe. Jednak użytkownik (właściciel) bez FCI może również ręcznie klasyfikować pliki.
FCI to element dynamicznej kontroli dostępu, który klasyfikuje pliki, przypisując im tagi, od których zależy stosowanie zasad DAC..
Technologia po raz pierwszy Infrastruktura klasyfikacji plików Wprowadzono w systemie Windows Server 2008 R2. Jakie możliwości zapewniła? Korzystając z FCI, możliwe jest wdrożenie różnych scenariuszy przetwarzania dokumentów w magazynach plików (w tym zawierających informacje poufne): gromadzenie, szyfrowanie, przesyłanie, archiwizacja, wysyłanie wzdłuż trasy i usuwanie plików. Korzystając z FCI, możesz na przykład zaimplementować skrypt, który pozwala automatycznie przesyłać pliki z drogiego magazynu do tańszego i wolniejszego na podstawie klasyfikacji plików lub, na przykład, automatycznie uniemożliwiać dostęp do plików po pewnym czasie.
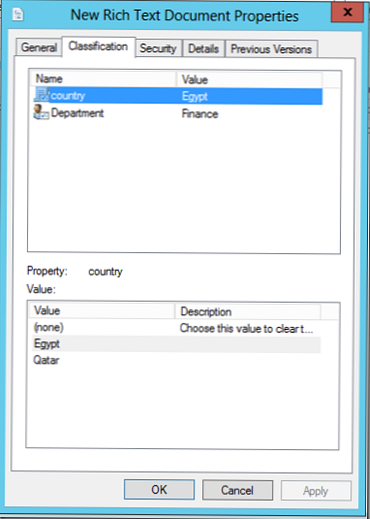
Poniższy zrzut ekranu pokazuje przykład pliku zaklasyfikowanego jako należący do kraju Egiptu i działu „Finanse”. Atrybutami klasyfikacyjnymi może być absolutnie wszystko: na przykład priorytet, prywatność, lokalizacja, organizacja itp..
Jak ręcznie sklasyfikować plik lub katalog
Pliki i katalogi można klasyfikować ręcznie, otwierając okno właściwości obiektu i wybierając opcję „KlasyfikacjaW naszym przykładzie z rozwijanej listy predefiniowanych wartości możesz wybrać inne wartości dla atrybutów kraju i działu.
Automatyczna klasyfikacja
Aby skonfigurować automatyczną klasyfikację obiektów w systemie Windows Server 2012, musisz użyć konsoli Menedżera serwera, aby zainstalować rolę Serwer plików (serwer plików).
Instalując komponent Menedżer zasobów serwera plików (FSRM), otwórz odpowiednią konsolę MMC, a wśród dobrze znanego kontyngentu, ochrony plików i grup zarządzania plikami zobaczysz nową podsekcję Zarządzanie klasyfikacją (zarządzanie klasyfikacją), który z kolei składa się z dwóch sekcji:
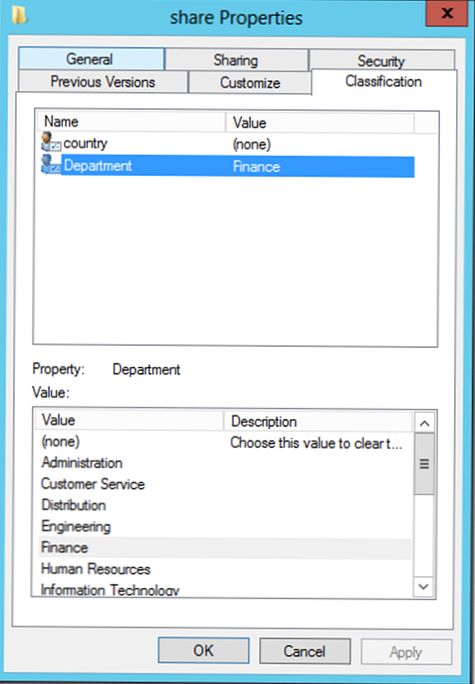
- Właściwości klasyfikacji - służy do tworzenia atrybutów klasyfikacji (w naszym przykładzie są to atrybuty kraju i departamentu, które mają status globalny, ponieważ są publikowane w AD)
- Reguły klasyfikacji - automatyczne reguły klasyfikacji

Aby skonfigurować automatyczną klasyfikację dokumentów, musisz utworzyć regułę klasyfikacji.
Jednym ze sposobów organizacji automatycznej klasyfikacji plików na podstawie lokalizacji jest właściwość klasyfikacji - FolderWykorzystanie. Jest to predefiniowana właściwość przechowywana w sekcji Właściwości klasyfikacji. Domyślnie definiuje 4 typy danych:
- Dane aplikacji - Dane aplikacji
- Kopie zapasowe - kopie zapasowe danych
- Dane grupy - Dane grupy
- Pliki użytkownika - Pliki użytkownika
Możesz tutaj tworzyć własne typy danych..
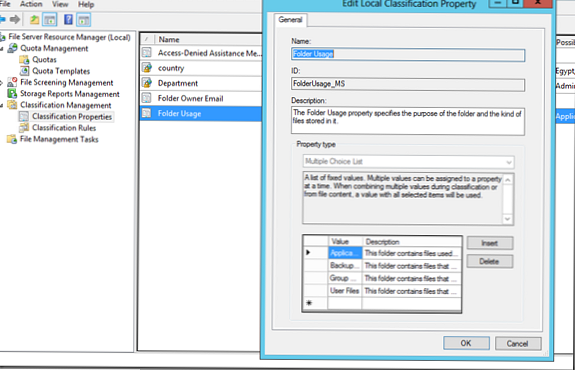
Tutaj stworzymy własne typy folderów dla działu finansowego (finansowego) i inżynieryjnego (inżynierii), a następnie musimy ustalić, które pliki należą do którego działu (typu danych). Aby to zrobić, kliknij puste miejsce w konsoli FSRM w obszarze KlasyfikacjaWłaściwości i wybierz SetFolderZarządzanieWłaściwości
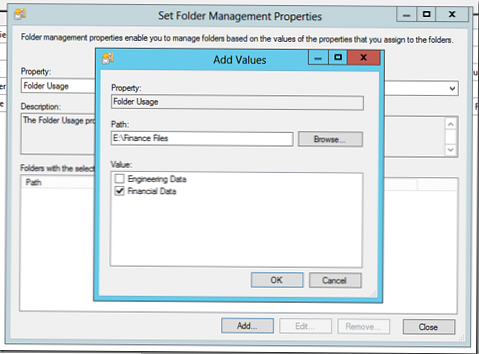
Wybierz właściwość FolderWykorzystanie i określ foldery, które będą używane przez każdy dział lub zawierające określony typ danych. Należy jednak rozumieć, że w tym przypadku nie jest skonfigurowana klasyfikacja plików (skonfigurujemy ją później), określimy własność folderów, których będziemy używać w regule klasyfikacji
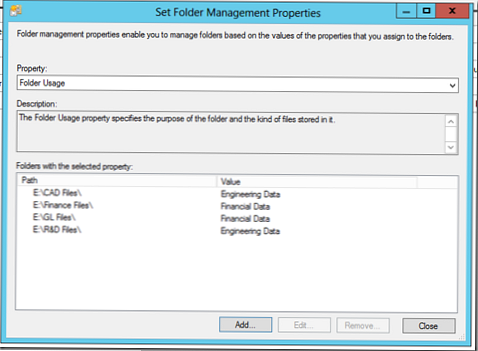
Ustawiliśmy to w następujący sposób:
Utwórz regułę klasyfikacji danych
Nadszedł czas w sekcji KlasyfikacjaZasady utwórz nową regułę (menu kontekstowe Utwórz regułę klasyfikacji):
Wskaż nazwę reguły (tworzymy regułę klasyfikującą pliki jako należące do działu finansów).
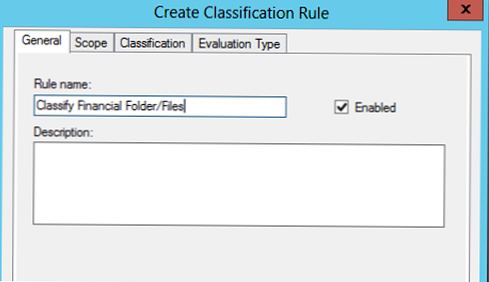
Tab Zakres wskazujemy katalogi, które należy wziąć pod uwagę przy przeprowadzaniu klasyfikacji, wybierzemy regułę utworzoną wcześniej FinansoweDane (automatycznie dodaje wszystkie wcześniej wybrane foldery), możesz także dodawać katalogi ręcznie (w przykładzie jest to E: \ share1).
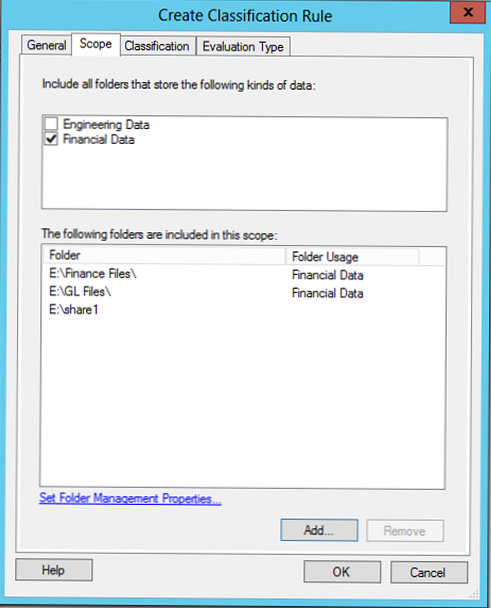
Tab Klasyfikacja Możesz wybrać jedną z dwóch metod klasyfikacji:
- Klasyfikacja folderów - klasyfikacja na podstawie katalogu (atrybuty dotyczą wszystkich plików katalogu)
- Klasyfikacja treści - klasyfikacja według zawartości pliku. W takim przypadku wszystkie pliki w katalogu są wyszukiwane według słów kluczowych, wzorów lub wyrażeń regularnych (numery projektów, karty kredytowe, identyfikatory działów itp.).
Zrzut ekranu pokazuje regułę klasyfikacji opartą na katalogach, reguła klasyfikacji według zawartości zostanie omówiona poniżej.
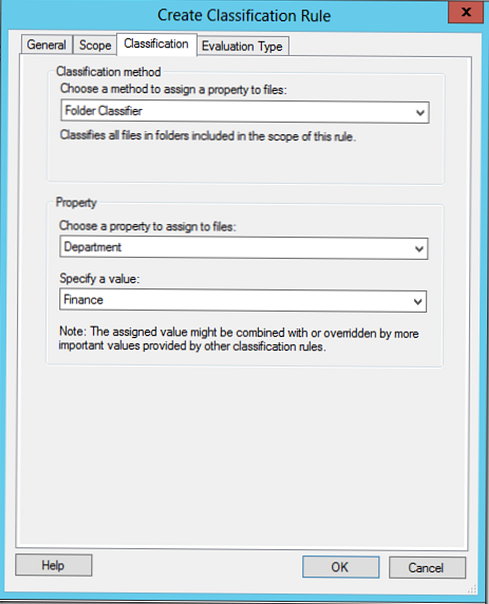
Tab Typ wartości oceny Wskazana jest procedura stosowania i ponownego stosowania reguł klasyfikacji do plików. W poniższym przykładzie wskazaliśmy, że system może zastąpić bieżącą klasyfikację, dlatego gwarantujemy, że klasyfikacja użytkownika zostanie zastąpiona przez regułę korporacyjną.

W poniższej regule klasyfikacji utworzymy regułę klasyfikacji na podstawie zawartości pliku:
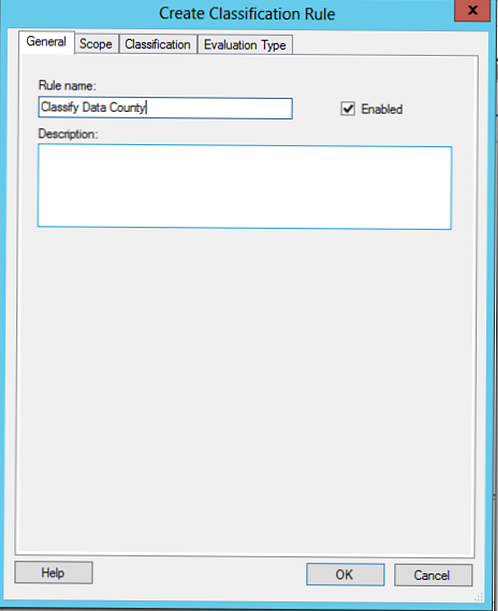
Ta reguła klasyfikuje dane według kraju, dlatego dodamy do niej katalogi zarówno działu inżynieryjnego, jak i finansowego.
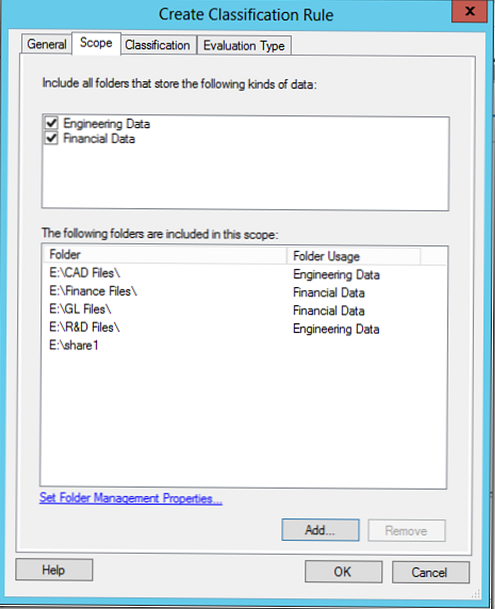
W tej regule klasyfikacji, na podstawie zawartości pliku, spróbujemy sklasyfikować dane związane z krajem Egiptu.
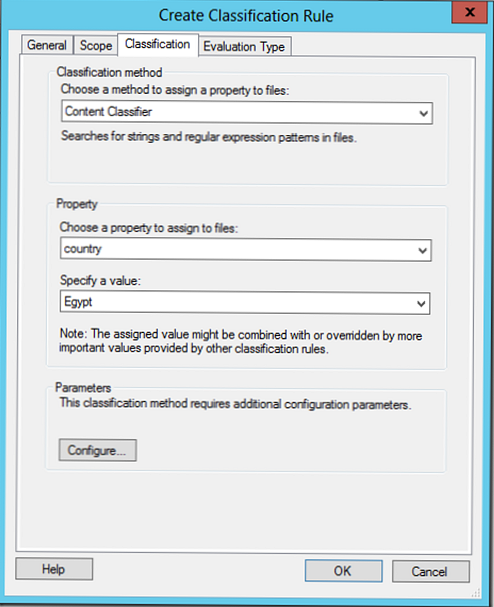
W sekcji Parametry wybierz Konfiguruj. W wyświetlonym oknie możesz wyszukiwać na podstawie wyrażeń regularnych, ciągu znaków lub ciągu rozróżniającego małe i wielkie litery..
Za pomocą wyrażeń regularnych możesz wyszukiwać w dokumentach tekstowych (w tym w pliku tiff) według różnych kryteriów, na przykład:
- Obecność korzeni w słowie, nie zwracanie uwagi na przypadki i sufiksy
- Obecność słów lub wyrażeń w losowej kolejności
- Dostępność danych w określonym formacie, takich jak numery kart kredytowych, numery telefonów, dane paszportowe lub adresy e-mail
- Warunki spotkania dla określonej ilości wymaganych danych w pliku (na przykład co najmniej 3 numery kart kredytowych lub telefonów)
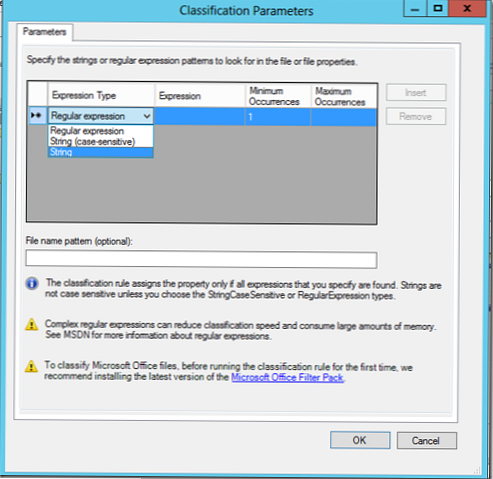
W naszym przykładzie przeszukamy dokumenty przy użyciu słowa kluczowego Egipt, a jeśli zostanie znalezione, plik powinien zostać sklasyfikowany według tej reguły (możesz określić minimalną i maksymalną liczbę wystąpień słowa kluczowego w dokumencie).
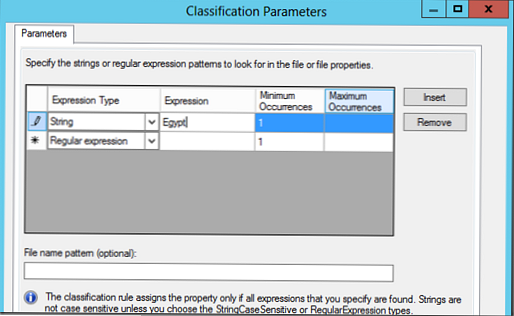
Tak więc stworzyliśmy dwie reguły klasyfikacji:
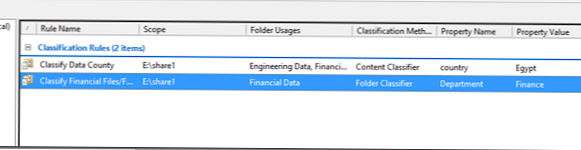
Teraz spróbujmy uruchomić automatyczną klasyfikację plików. Załóżmy, że mamy 2 pliki, z których jeden zawiera słowo Egipt, a drugi nie. Pliki te są umieszczane w katalogach „Pliki finansowe” i „Pliki R&D”, co widać w tej chwili, że nie są w żaden sposób klasyfikowane..
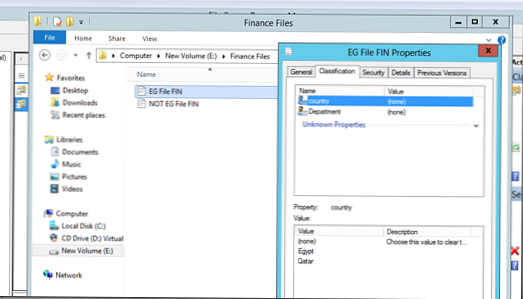
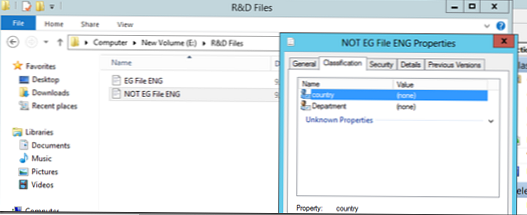
Uruchom nasze zasady klasyfikacji (Uruchom klasyfikację ze wszystkimi regułami):
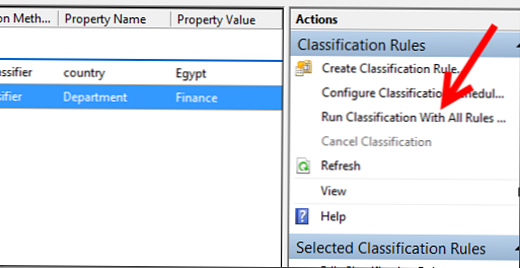
Wyniki reguł można znaleźć w raportach w raportach..

Jak widać, wszystko działało poprawnie, do pliku ze słowem kluczowym został przypisany właściwy kraj, a atrybut Finance do całej zawartości katalogu działu finansów.
Na tym etapie nie przeprowadzono żadnych operacji z plikami niejawnymi; zostały one po prostu oznaczone atrybutami, których potrzebowaliśmy. W przyszłości, w oparciu o klasyfikację plików, możesz wykonywać z nimi różne operacje, w szczególności szyfrować pliki przy użyciu AD RMS (przykład zastosowania opisano w artykule Szyfrowanie plików przy użyciu AD RMS w oparciu o infrastrukturę klasyfikacji plików systemu Windows Server 2012) lub kontrolować dostęp do nich za pośrednictwem systemu Windows Dynamiczna kontrola dostępu Server 2012. Rozważymy te aspekty w następnych artykułach z serii..

{kind=link}