

Wielu blogerów szuka odpowiedzi na to pytanie: „Jak pozbyć się zduplikowanych stron?”, Aby usunąć zduplikowane strony ich witryny z wyników wyszukiwarek. Zduplikowane strony znajdują się w indeksie wyszukiwarek, gdzie są one obecne wraz z główną promowaną stroną.
Istnieje wiele takich stron, jednocześnie wyszukiwarka będzie musiała uszeregować te same strony w wynikach wyszukiwania. W tym celu wyszukiwarka może nałożyć sankcje na stronie głównej, obniżając ją w wynikach wyszukiwania. W ten sposób zduplikowane strony mają szkodliwy wpływ na promocję stron witryny w wyszukiwarce.
Treść- Moja historia o robieniu zduplikowanych stron
- Wyszukaj zduplikowane strony
- Zakaz indeksowania w pliku robots.txt
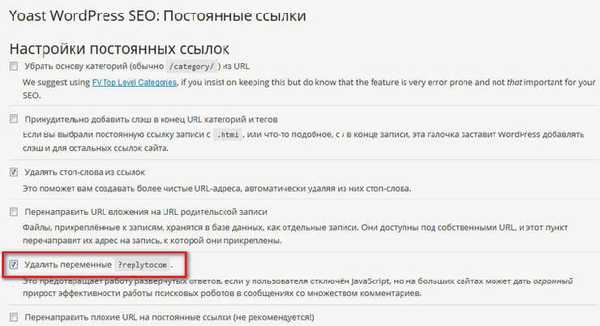
- Dodanie parametru replytocom do narzędzi dla webmasterów
- Wtyczka do komentarzy wątków WordPress do komentarzy do drzewa
- Wtyczka SEO WordPress firmy Yoast do usuwania replytocom
- Przekierowanie 301, aby usunąć odpowiedź
- Ustawienia wtyczki SEO
- Ręczne usuwanie duplikatów stron
- Jak duplikaty są usuwane z mojej witryny
- Kolejny sposób radzenia sobie ze zduplikowanymi stronami
- Wnioski z artykułu
Duplikaty stron mogą kopiować pełną treść lub tylko częściową zawartość strony głównej. W szczególności sam WordPress CMS tworzy w niektórych przypadkach zduplikowane strony, na przykład dobrze znany „replytocom” (komentarz, odpowiedź na komentarz, replika).
Jeśli w Twojej witrynie znajdują się komentarze drzewa, wówczas w takim przypadku każdy komentarz utworzy duplikat strony. Dlatego jeśli w indeksie wyszukiwarek znajdują się zduplikowane strony witryny, konieczne będzie usunięcie takich stron z wyników wyszukiwarek.
Obecność zduplikowanych stron w wyszukiwaniu szkodzi witrynie, gdy jest promowana w wyszukiwarkach. Wyszukiwarki obniżają pozycję witryny, zmniejsza się tzw. Waga strony, pogarsza się indeksowanie witryny itp..Wyszukiwarka Google zwraca szczególną uwagę na obecność zduplikowanych stron, obniżając pozycję witryny w obecności dużej ich liczby. Nie będę już teoretyzować na ten temat, ale raczej opowiem o tym, jak walczę z duplikatami stron na przykładzie mojej witryny - vellisa.ru.
Moja historia o robieniu zduplikowanych stron
Na początku wiosny 2013 r. Moja witryna skończyła rok, w tym czasie ruch w witrynie wynosił około 2000 osób dziennie. Potem ruch w witrynie zaczął spadać. Już w połowie maja frekwencja ledwie przekroczyła 1000 odwiedzających dziennie..
Wiosną 2013 r. Wielu blogerów, dzięki wprowadzeniu nowych algorytmów, zmniejszyło frekwencję w Google. W mojej witrynie ruch z wyszukiwarki Google spadł o około 40%. W moim przypadku na spadek ruchu wpłynęły wprowadzenie nowych algorytmów, a także niektóre zmiany, które wprowadziłem w tym czasie na mojej stronie.
Myśląc, postanowiłem zwrócić poprzedni ruch z mojej witryny. Latem wykonałem to zadanie, we wrześniu moja witryna ponownie osiągnęła średni ruch 2000 odwiedzających dziennie. Ponadto ruch do mojej witryny nadal rósł..
Wszystko wydaje się być w porządku, ale faktem jest, że wzrost frekwencji nastąpił głównie dzięki wyszukiwarce Yandex. Jeśli wcześniej odsetek odwiedzających, którzy przyszli na stronę z Yandex i wyszukiwarki Google, wynosił 3 do 1 (przybliżony stosunek, z grubsza) na korzyść Yandex, co z grubsza odpowiada udziałowi wyszukiwarek w Runet, to stosunek ten wzrósł do 5 do 1. Istniała silna zależność od pojedyncza wyszukiwarka.
Frekwencja w Google rosła bardzo powoli, dopiero wiosną 2014 roku osiągnęła poziom z ubiegłego roku. Ale wtedy cały rok pisałem nowe artykuły. Okazuje się, że Yandex odpowiednio zareagował na dodanie nowych artykułów na stronie, czego nie można powiedzieć o Google.
W grudniu 2013 r. Musiałem zainstalować nowy szablon na swojej stronie, ponieważ w poprzednim temacie nie mogłem zmienić struktury mojej witryny. I tak musiałem wykonać te czynności.
Następnie zwróciłem uwagę na zduplikowane strony w indeksie wyszukiwarek. Wcześniej wiedziałem o tym problemie, czytałem o sposobach jego rozwiązania, ale jeszcze nic nie zrobiłem..
W każdym razie nie wyłączałbym komentarzy drzewa w mojej witrynie, ponieważ byłoby to niewygodne dla odwiedzających witrynę i nie chciałem używać wtyczek do usuwania duplikatów stron.
W rezultacie kod został zainstalowany w pliku htaccess, a niektóre dyrektywy zostały usunięte z pliku robots.txt (powiem więcej o tym, co zrobiłem poniżej). Stopniowo liczba zduplikowanych stron w mojej witrynie zmniejszyła się w wynikach wyszukiwania.
W marcu 2014 r. Dodałem parametr „replytocom” do narzędzi Google dla webmasterów, a w maju dodałem tam inny parametr: „kanał”.
W tej chwili w mojej witrynie nie było zduplikowanych stron w wynikach wyszukiwarki Google, które mają zmienną answertocom w swoim adresie, ale wcześniej istniała ogromna liczba takich stron (kilka tysięcy).
Wreszcie byłem mile zaskoczony wzrostem, około 2-krotnym wzrostem obecności Google. Teraz stosunek między wyszukiwarkami wyniósł około 2 do 1 na korzyść Yandex.
Tak więc, z własnego doświadczenia, dowiedziałem się, jaki wpływ może mieć na promocję witryny, obecność zduplikowanych stron w indeksie wyszukiwarki.
To prawda, że należy wziąć pod uwagę, że wyszukiwarki pozycjonują strony w wynikach wyszukiwania na wiele sposobów. W związku z tym ruch w Twojej witrynie może nie być znaczny. W każdym razie usunięcie zduplikowanych stron z wyników wyszukiwania będzie miało pozytywny wpływ na Twoją witrynę..
Wyszukaj zduplikowane strony
Aby wyszukać zduplikowane strony w witrynie, wpisz wyrażenie „site: vellisa.ru” w polu wyszukiwania (zamiast „vellisa.ru” wpisz nazwę swojej witryny). Przejdź do ostatniej strony wyników wyszukiwania, w tym przypadku mam 19 stron. Zapamiętaj numer tej strony, abyś mógł później szybko przejść do tej strony.
Na ostatniej stronie wyników wyszukiwania, poniżej ostatniego wyniku wyników wyszukiwania, zobaczysz ogłoszenie, w którym zostaniesz poinformowany, że wyszukiwarka ukryła niektóre wyniki, które są bardzo podobne do wyników już przedstawionych powyżej. Następnie kliknij link „Pokaż ukryte wyniki”.

Następnie pierwsza strona wyników wyszukiwania zostanie ponownie otwarta. Przejdź od razu do strony, którą pamiętasz, w moim przypadku jest to strona 19. Na tej lub na następnej stronie zobaczysz zduplikowane strony swojej witryny.
Ten obraz pokazuje zduplikowane strony z linkami „feed” i „tag” w adresie URL. Również w wynikach wyszukiwania mogą być duplikaty z „replytocom”, „strona” i kilkoma innymi parametrami.

Innym dużym problemem, jeśli witryna używa komentarzy drzewa, jest ogromna liczba stron ze zmienną answertocom wygenerowaną przez sam WordPress CMS.
Możesz sprawdzić dostępność stron z replytocom w ten sposób: wpisz wyrażenie „site: vellisa.ru replytocom” (bez cudzysłowów) w pasku wyszukiwania Google. Zamiast „vellisa.ru” wstaw nazwę swojej witryny.
W mojej witrynie nie ma zduplikowanych stron z odpowiedzią, mimo że w mojej witrynie znajdują się komentarze do drzewa. Jako przykład wezmę stronę mojej dziewczyny Julii (inet-boom.ru), mam nadzieję, że nie będzie się za to obrażać.
Na tym obrazie, na samym końcu linku, po adresie strony, zobaczysz koniec linku - „? Replytocom = 3734”. Liczby na końcu adresu zmienią się w zależności od numeru komentarza.

W indeksie wyszukiwarki może znajdować się ogromna liczba takich stron. W związku z tym trzeba będzie walczyć z odpowiedzią.
Co trzeba będzie zrobić?
- Sprawdź duplikaty stron w indeksie wyszukiwarki.
- Zamknij niezbędne parametry z indeksowania w pliku robots.txt.
- Dodaj ustawienia do paska narzędzi Google Webmaster.
Te wymagania będą musiały zostać spełnione bezbłędnie. Reszta działań będzie zależeć od wybranej metody zwalczania duplikatów stron..
Musisz dodać swoją witrynę do narzędzi Google i Yandex dla webmasterów, aby rozwiązać problem pozbywania się duplikatów stron za pomocą tych narzędzi wyszukiwarki.
Zakaz indeksowania w pliku robots.txt
Aby zabronić indeksowania niektórych parametrów, które wpływają na wygląd zduplikowanych stron podczas wyszukiwania, do pliku robots.txt są dodawane dyrektywy. Podczas korzystania z dyrektywy Disallow wydawane jest polecenie przeszukujące roboty, aby zabronić indeksowania.
Polecenia zapobiegające indeksowaniu w pliku robots.txt mogą wyglądać mniej więcej tak (w tym przykładzie część pliku):

Dyrektywy ze znakiem zapytania (?) Są zwykle obecne, jeśli w witrynie tworzone są tak zwane łącza CNC, za pomocą których zmienia się adres URL strony internetowej. Istnieje również polecenie zakazujące indeksowania linków za pomocą zmiennej replytocom.
Jeśli wyszukiwarka Yandex, ogólnie rzecz biorąc, jest zgodna z dyrektywami zawartymi w pliku robots.txt, to w przypadku wyszukiwarki Google wszystko jest znacznie bardziej skomplikowane. Roboty Google indeksują wszystko, pomimo zakazów określonych w pliku robots.txt.
Wtyczka do optymalizacji SEO ma możliwość zamykania nagłówka, tagów, archiwów, stron wyszukiwania itp. Za pomocą tagu „noindex”. To prawda, że roboty nie zawsze podążają za tymi robotami.
Dodanie parametru replytocom do narzędzi dla webmasterów
W narzędziu Google dla webmasterów przejdź do strony Narzędzi dla webmasterów. W prawej kolumnie „Pasek narzędzi witryny” najpierw kliknij przycisk „Skanuj”, a następnie kliknij przycisk „Ustawienia adresu URL”.
Na tej stronie możesz dodać nowe parametry lub zmienić już dodane parametry do przetwarzania przez roboty wyszukiwania Google. W zależności od ustawień robot indeksujący Googlebot zignoruje niektóre parametry podczas wchodzenia na strony witryny w indeksie wyszukiwarki.
- Aby dodać nowy parametr, kliknij przycisk „Dodaj parametr”.

- Następnie otworzy się okno „Dodaj parametr”..
- W polu parametru (rozróżniana jest wielkość liter) dodaj nowy parametr, w tym przypadku „replytocom”.
- Na pytanie: „Czy ten parametr zmienia treść strony, którą widzi użytkownik?”, Użytkownik odpowiada: „Tak, parametr zmienia, reorganizuje lub ogranicza zawartość strony”.
- Odpowiadając na pytanie: „Jak ten parametr wpływa na zawartość strony?”, Wybierz opcję odpowiedzi: „Inne”.
- Na pytanie: „Które adresy URL zawierające ten parametr powinny indeksować Googlebot”, odpowiedz: „Brak adresów URL”.
- Następnie kliknij przycisk „Zapisz”.

Podobnie możesz dodać inne parametry. Jeśli parametr znajduje się już na liście, to aby zmienić jego ustawienia, musisz kliknąć link „Zmień”.

Po dodaniu parametru replytocom do panelu webmastera musisz usunąć coś takiego jak dyrektywa „Disallow: / *? Replytocom” (jeśli jest obecny w pliku robota) z pliku robots.txt, aby googlebot mógł podążać za linkami z tym parametrem, i usunąłem je z indeksu.
Jeśli Twoja witryna nie ma zduplikowanych stron z tym parametrem, możesz pozostawić taką dyrektywę w pliku robots.txt.
Stopniowo powielone strony zostaną usunięte z indeksu wyszukiwarki. Jeśli istnieje wiele zduplikowanych stron, w takim przypadku proces usuwania zduplikowanych stron potrwa dość długo, być może nawet w ciągu kilku miesięcy.Wtyczka do komentarzy wątków WordPress do komentarzy do drzewa
Ponieważ pojawienie się replytocom jest ułatwione dzięki komentarzom drzewa, niektórzy użytkownicy zazwyczaj wyłączają je na swojej stronie. Po wyłączeniu komentarzy do drzewa, szczególnie jeśli artykuły na stronie są aktywnie komentowane, uzyskuje się bardzo niewygodną nawigację. Odwiedzającemu, czasami nie jest wcale jasne, kto, gdzie, do kogo, co odpowiedział.
Wtyczka WordPress Thread Comment rozwiązuje problem komentarzy do drzewa w WordPress. Komentarze drzewa pozostają na stronie, bez dodanych zmiennych replytocom. Wtyczka wyświetla link z komentarzem przez javascript, więc wyszukiwarki nie indeksują tego linku.
Nowe zmienne replytocom nie będą już pojawiać się w indeksie wyszukiwarki, a stare zmienne będą musiały być stopniowo usuwane z indeksu wyszukiwarek.
Osobiście nie podobał mi się wygląd komentarzy w tej wtyczce. Nie korzystałem z tej wtyczki w mojej witrynie. Zwracam uwagę, że Alexander Borisov zalecił wtyczkę WordPress Thread Comment do walki z odpowiedzią.
Wtyczka SEO WordPress firmy Yoast do usuwania replytocom
Wtyczka WordPress SEO firmy Yoast, dość wydajna wtyczka do optymalizacji strony SEO, między innymi, pozwala usunąć zmienne replytocom ze strony. Jednocześnie komentarze do drzewa pozostaną w Twojej witrynie.
Po zainstalowaniu wtyczki WordPress SEO przez Yoast na swojej stronie, w ustawieniach wtyczek, w sekcji „Permalinks”, musisz aktywować „Usunąć zmienne? Replytocom”.
Następnie stopniowo powielane strony z „smarkiem” replytocom zostaną usunięte z indeksu Google.
Ponieważ na mojej stronie jest zainstalowana wtyczka All in One SEO Pack iz jakiegoś powodu nie chcę jeszcze przechodzić na WordPress SEO przez wtyczkę Yoast, nie użyłem tej opcji do walki z duplikatami stron.
Przekierowanie 301, aby usunąć odpowiedź
Jest to prawdopodobnie najbardziej radykalny sposób radzenia sobie z odpowiedzią. Użyłem tej konkretnej metody.
Po zmianie szablonu Larisa Web-Cat zasugerowała użycie przekierowań 301 do walki z przyjmowaniem odpowiedzi. Przed zmianą szablonu na stronie nie odważyłem się skorzystać z tej metody.
Teraz mogę powiedzieć, że gdy korzystam z przekierowania 301, a także po niektórych działaniach, o których napiszę poniżej, moja strona pomyślnie poradziła sobie z duplikatami answertocom.
Na tym obrazku widać, że w mojej witrynie nie ma zduplikowanych stron ze zmienną replytocom, pomimo faktu, że w mojej witrynie są komentarze drzewa, bez użycia specjalnych wtyczek.

Aby użyć przekierowania 301, musisz wstawić specjalny kod do pliku „htaccess”, który znajduje się w folderze głównym witryny. Folder główny witryny to folder witryny zawierający foldery „wp-admin”, „wp-content”, „wp-obejmuje” itp..
W pliku htaccess poniżej linii „RewriteBase /” należy wstawić następujący kod:
RewriteCond% QUERY_STRING replytocom = RewriteRule ^ (. *) $ / $ 1? [R = 301, L]Uwaga! Przed osadzeniem tego kodu oryginalny plik htaccess na komputerze. Jeśli popełnisz błąd, coś pójdzie nie tak, możesz zastąpić zmodyfikowany plik htaccess oryginalnym plikiem za pomocą menedżera plików na swoim serwerze hostingowym lub FTP przez FileZilla.
Jeśli wystąpi problem, zamiast witryny zobaczysz „biały ekran śmierci”. Zastąpienie zmodyfikowanego pliku oryginalnym plikiem htaccess przywróci funkcjonalność Twojej witryny.
Po wstawieniu kodu należy sprawdzić działanie przekierowania 301. Aby to zrobić, najpierw musisz wstawić link zawierający odpowiedź na pasku adresu przeglądarki, a następnie sprawdzić wynik przejścia. Po przejściu link na otwartej stronie internetowej będzie musiał zmienić się na oryginalny link, który nie zawiera zmiennej replytocom w adresie URL.
Następnie musisz zrobić jeszcze dwie rzeczy. Najpierw musisz usunąć dyrektywy z pliku robots.txt zawierającego zakaz indeksowania stron ze znakiem zapytania. Dyrektywy są usuwane, jeśli używasz tej metody..

Następnie musisz dodać parametr replytocom do „Narzędzi Google dla webmasterów”, jak napisałem powyżej w tym artykule.
Ustawienia wtyczki SEO
Aby zapobiec indeksowaniu stron archiwów, kategorii, tagów, stron 404, stron wyszukiwania, paginacji (nawigacja strona po stronie), we wtyczce Wszystko w jednym pakiecie SEO musisz aktywować elementy, aby dodać argumenty noindex, follow i noindex, nofollow (do nawigacji strona po stronie).
We wtyczce WordPress SEO firmy Yoast parametry indeksowania wyszukiwarek będą wyglądać następująco: noindex, śledź.
Teraz musisz uzbroić się w cierpliwość i czekać, aż Google usunie zduplikowane strony ze swojego indeksu. Jeśli nie chcesz długo czekać lub w Twojej witrynie pozostało niewiele duplikatów, możesz przyspieszyć ich usuwanie.
Ręczne usuwanie duplikatów stron
Możesz ręcznie dodać linki do zduplikowanych stron do Narzędzi dla webmasterów, aby usunąć je z indeksu wyszukiwarki. Gdy w wynikach wyszukiwania nie było tak wielu zduplikowanych stron w mojej witrynie, dodałem ręcznie znalezione wyniki, aby szybciej je usunąć z indeksu.
- Na stronie „Narzędzi dla webmasterów”, w prawej kolumnie „paska narzędzi witryny”, najpierw kliknij przycisk „Indeks Google”, a następnie kliknij przycisk „Usuń adresy URL”.
- Następnie otworzy się strona „Usuń adresy URL”. Na tej stronie musisz kliknąć przycisk „Utwórz nowe żądanie usunięcia”.

- Pod przyciskiem otworzy się pole, w którym można wstawić link. Następnie musisz kliknąć przycisk „Kontynuuj”.

- Następnie otwiera się nowa strona, na której wyświetlony zostanie usunięty adres URL. W elemencie „Przyczyna” wybierz tę opcję: „Usuń stronę z wyników wyszukiwania i z pamięci podręcznej”. Następnie kliknij przycisk „Prześlij żądanie”.

- Na stronie Usuń adresy URL zobaczysz dodane linki oczekujące na usunięcie. Dokładnie w ten sposób możesz dodać następujący link, aby usunąć go z wyników wyszukiwania i z pamięci podręcznej wyszukiwarki Google.

Problem istnieje, może mieć negatywny wpływ na promocję witryny, więc administrator witryny będzie musiał pozbyć się duplikatów stron, aby uzyskać pozytywny wynik.
Minął miesiąc od publikacji tego artykułu, teraz nadszedł czas na uzupełnienie publikacji o nowe informacje.
Jak duplikaty są usuwane z mojej witryny
Teraz powiem ci dokładnie, jak w tej chwili odbywa się walka z duplikatami stron w mojej witrynie.
- Usunąłem niektóre zakazujące dyrektywy z pliku robots.txt, aby umożliwić robotom dostęp do niektórych katalogów mojej witryny.
- We wtyczce do optymalizacji SEO (AIOSP) zauważyłem punkty za dodanie robotów z metatagiem dla odpowiednich stron witryny. Robot poruszający się na taką stronę zobaczy metatag zakazujący i nie zaindeksuje tej strony.
Aby to zrobić, dostęp do niektórych stron w pliku robota został otwarty, więc robot poszedł na tę stronę i zobaczył następujące metatagi:
meta name = „robots” content = „noindex, nofollow” meta name = „robots” content = „noindex, follow”
Dlatego robot wyszukujący nie zaindeksuje strony za pomocą takich metatagów. Wcześniejsze trafienia w indeksie stron będą stopniowo usuwane z wyników wyszukiwania..
- Opcje Replytocom zostały dodane do panelu Google dla webmasterów.
- Dodałem następujący kod do pliku htaccess:
RewriteCond% QUERY_STRING replytocom = RewriteRule ^ (. *) $ / $ 1? [R = 301, L] RewriteRule (. +) / Feed / 1 $ [R = 301, L] RewriteRule (. +) / Strona z komentarzem / 1 $ [R = 301, L] RewriteRule (. +) / Trackback / 1 $ [R = 301, L] RewriteRule (. +) / Komentarze / 1 $ [R = 301, L] RewriteRule (. +) / Załącznik / 1 $ [R = 301, L] RewriteCond% QUERY_STRING ^ załącznik_id = [NC] RewriteRule (. *) 1 $? [R = 301, L]
Ten kod zawiera 301 przekierowań z answertocom, a także przekierowania z innymi parametrami, które wziąłem ze strony Aleksandra Borysowa. Jak rozumiem, autorem przekierowań dla innych parametrów jest znany bloger Alexander Alaev (Alaich).
Odpowiednie dyrektywy (kanał, komentarze, trackback itp.) Dla parametrów dodanych do pliku htaccess zostały usunięte z pliku robots.txt.
Następnie robot wyszukujący przechodzący do zduplikowanej strony, która ma takie parametry w adresie URL, zostanie przekierowany za pomocą przekierowania 301 na oryginalną stronę mojej witryny.
- Kod pliku został dodany do pliku functions.php, aby zapobiec pojawianiu się nowych ujęć z replytocom, który został znaleziony w Internecie przez gościa mojej witryny, Anton Lapshin:
funkcja replace_reply_to_com ($ link) return preg_replace ('/href=\'(.*(\?|&)replytocom=(\d+)#respond)/', 'href = \' # comment- $ 3 ', $ link ); add_filter ('comment_reply_link', 'replace_reply_to_com');Czy będziesz musiał wkleić ten kod do pliku „Funkcje tematu” (functions.php) przed tagiem zamykającym?>.
Po wstawieniu kodu, gdy najedziesz myszką na przycisk „Odpowiedz” w komentarzach, zmienna responsetocom nie będzie już wyświetlana w łączu, który będzie widoczny w lewym dolnym rogu okna przeglądarki. Dlatego nowe linki z tym parametrem nie zostaną dodane do indeksu wyszukiwarek.
Przed wprowadzeniem zmian należy wykonać kopię zapasową pliku funkcji motywu..
Wszystkie te ustawienia działają głównie w wyszukiwarce Google. W Yandex stosunek liczby stron załadowanych przez robota do stron wyszukiwania w mojej witrynie jest w tej chwili optymalny.
Kolejny sposób radzenia sobie ze zduplikowanymi stronami
Znalazłem w Internecie inny sposób na usunięcie duplikatów stron z wyników wyszukiwania. Za pomocą tego kodu do niektórych stron witryny zostanie dodany metatag robota noindex, nofollow, aby uniemożliwić indeksowanie takich stron.
Ten kod jest wstawiany natychmiast do pliku functions.php
function meta_robots () if (is_archive () lub is_category () lub is_feed () lub is_author () lub is_date () lub is_day () lub is_month () lub is_year () lub is_tag () lub is_tax () lub is_attachment () lub is_paged () lub is_search ()) echo "". ''. "\ n"; add działań („wp_head”, „meta_robots”);
Po dodaniu tego kodu, we wtyczce do optymalizacji SEO, musisz wyłączyć dodawanie metatagu Robot do tych stron. We wtyczce All in One SEO Pack - sekcja „Ustawienia indeksowania (noindex)”.
Następnie konieczne będzie usunięcie odpowiednich dyrektyw zakazujących z pliku robota..
W ten sposób możesz zamknąć niezbędne strony przed indeksowaniem. Aby pozbyć się zduplikowanej odpowiedzi, musisz użyć jednej z metod opisanych w tym artykule. Oprócz korzystania z przekierowań i wtyczek możliwe będzie również dołączanie linków do komentarzy w tagu span, aby nie były one indeksowane przez wyszukiwarki.
Po zakończeniu ustawień będziesz musiał od czasu do czasu monitorować proces usuwania zduplikowanych stron z Twojej witryny.
Wnioski z artykułu
Webmaster powinien zwrócić uwagę na obecność zduplikowanych stron witryny, a jeśli zostaną znalezione, podejmij środki, aby usunąć je z wyników wyszukiwania, ponieważ negatywnie wpływają na promocję witryny. Z tego powodu witryna może podlegać sankcjom w wyszukiwarkach..
Powiązane publikacje:- Jak przenieść witrynę do HTTPS
- Jak zwiększyć ruch na stronie
- Jak zainstalować reklamy na stronie
- Przegląd szybkiego hostingu AdminVPS
- Wtyczka Breadcrumb NavXT - bułka tarta dla strony






{kind=link}