

W tym artykule przyjrzymy się konfiguracji konfiguracji przełączania awaryjnego z dwóch serwerów proxy kalmarów, aby użytkownicy mogli uzyskać dostęp do Internetu z sieci firmowej za pomocą prostego równoważenia obciążenia za pośrednictwem usługi Round Robin DNS. Aby zbudować konfigurację przełączania awaryjnego, utworzymy klaster HA przy użyciu utrzymywane przy życiu.
Klaster HA - Jest to grupa serwerów z wbudowaną redundancją, która jest tworzona w celu zminimalizowania przestojów aplikacji w przypadku problemów sprzętowych lub programowych jednego z członków grupy. W oparciu o tę definicję do działania klastra HA konieczne jest wdrożenie następujących elementów:
- Sprawdzanie statusu serwerów;
- Automatyczne przełączanie zasobów w przypadku awarii serwera;
Oba te zadania umożliwiają utrzymanie aktywności. Keepalived - demon systemowy w systemach Linux, który umożliwia organizację odporności na błędy usługi i równoważenie obciążenia. Odporność na awarie jest osiągana dzięki „ruchomemu” adresowi IP, który przełącza się na serwer zapasowy w przypadku awarii głównego. Protokół służy do automatycznego przełączania adresów IP między serwerami keepalived VRRP (Virtual Router Redundancy Protocol), jest standaryzowany, opisany w RFC (https://www.ietf.org/rfc/rfc2338.txt).
Treść
- Zasady VRRP
- Zainstaluj i skonfiguruj keepalived na CentOS
- Keepalived: monitoruj kondycję aplikacji i interfejsu
- Keepalived: testowanie awaryjne
Zasady VRRP
Przede wszystkim należy wziąć pod uwagę teorię i podstawowe definicje protokołu VRRP.
- VIP - wirtualny adres IP, wirtualny adres IP, który może automatycznie przełączać się między serwerami w przypadku awarii;
- Master - serwer, na którym VIP jest obecnie aktywny;
- Kopia zapasowa - serwery, na które VIP przełączy się w przypadku awarii kreatora;
- VRID - identyfikator wirtualnego routera, serwery połączone wspólnym wirtualnym adresem IP (VIP) tworzą tak zwany router wirtualny, którego unikalny identyfikator przyjmuje wartości od 1 do 255. Serwer może jednocześnie składać się z kilku identyfikatorów VRID, z unikalnymi wirtualnymi adresami IP dla każdego identyfikatora VRID.
Ogólny algorytm pracy:
- Serwer główny wysyła pakiety VRRP na zarezerwowany adres rozgłoszeniowy multiemisji (multiemisji) 224.0.0.18 z określonym interwałem, a wszystkie serwery podrzędne słuchają tego adresu. Wysyłanie w trybie multiemisji ma miejsce, gdy nadawcą jest jeden i może być wielu adresatów.
Jest ważne. Aby serwery działały w trybie multiemisji, sprzęt sieciowy musi obsługiwać transmisję ruchu multiemisji. - Jeśli serwer Slave nie odbiera pakietów, rozpoczyna procedurę wyboru Master, a jeśli przełączy się na stan Master według priorytetu, aktywuje VIP i trucizny darmowy ARP. Gratisitous ARP to specjalny rodzaj odpowiedzi ARP, która aktualizuje tabelę MAC podłączonych przełączników, aby poinformować Cię o zmianie własności wirtualnego adresu IP i adresu mac do przekierowywania ruchu.
Zainstaluj i skonfiguruj keepalived na CentOS
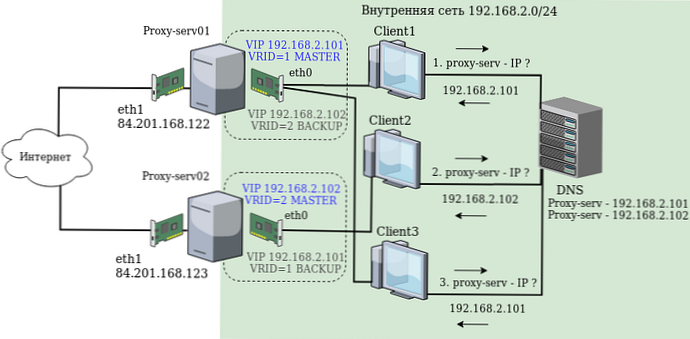
Instalacja i konfiguracja zostaną przeprowadzone na przykładzie serwery proxy-serv01 i proxy-serv02 na Centos 7 z zainstalowanym Squid. W naszym schemacie zastosujemy najprostszą metodę równoważenia obciążenia (równoważenie) - Round Robin DNS. W metodzie tej zakłada się, że dla jednej nazwy w DNS jest zarejestrowanych kilka adresów DNS, a klienci na żądanie otrzymują jeden adres naraz, a następnie inny. Dlatego będziemy potrzebować dwóch wirtualnych adresów IP, które zostaną zarejestrowane w DNS o tej samej nazwie i z którymi klienci się ostatecznie skontaktują. Schemat sieci:
Każdy serwer Linux ma dwa fizyczne interfejsy sieciowe: eth1 z białym adresem IP i dostępem do Internetu oraz eth0 w sieci lokalnej.
Następujące adresy są używane jako rzeczywiste adresy IP serwerów:
192.168.2.251 - dla proxy-server01
192.168.2.252 - dla proxy-server02
Następujące adresy są używane jako wirtualne adresy IP, które automatycznie przełączają się między serwerami w przypadku awarii:
192.168.2.101
192.168.2.102
Zainstaluj pakiet keepalived na obu serwerach za pomocą polecenia:
mniam zainstaluj keepalived
Po zakończeniu instalacji na obu serwerach edytuj plik konfiguracyjny
/etc/keepalived/keepalived.conf
Kolor podświetlonych linii o różnych parametrach:
| na serwerze proxy-serv01 | na serwerze proxy-serv02 |
 | 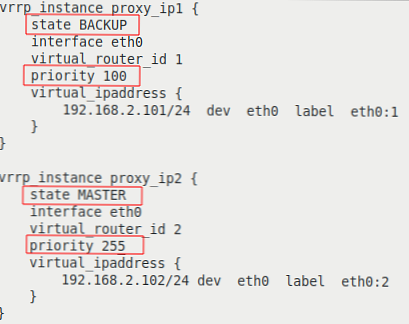 |
Przeanalizujemy opcje bardziej szczegółowo:
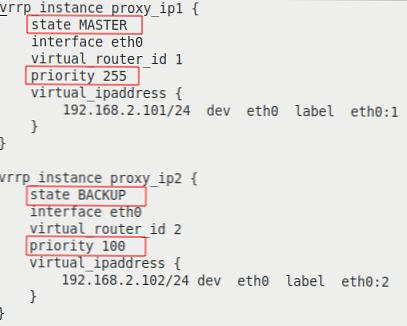
- vrrp_instance - Sekcja definiująca instancję VRRP;
- state - stan początkowy przy uruchomieniu;
- interfejs - interfejs, na którym będzie działać VRRP;
- virtual_router_id - unikalny identyfikator instancji VRRP, musi być zgodny na wszystkich serwerach;
- priorytet - ustawia priorytet przy wyborze MASTER, serwer o najwyższym priorytecie staje się MASTER;
- adres_ wirtualnego - blok wirtualnych adresów IP, które będą aktywne na serwerze w stanie MASTER. Musi być zgodny na wszystkich serwerach w instancji VRRP.
Jeśli bieżąca konfiguracja sieci nie zezwala na multiemisję, keepalived ma opcję użycia emisji pojedynczej, tj. wysyłanie pakietów VRRP bezpośrednio na serwery określone na liście. Aby użyć emisji pojedynczej, potrzebujesz opcji:
- unicast_src_ip - adres źródłowy pakietów VRRP;
- unicast_peer - blok adresów IP serwerów, na które będą wysyłane pakiety VRPP.
Zatem nasza konfiguracja definiuje dwie instancje VRRP, proxy_ip1 i proxy_ip2. Podczas normalnej pracy serwer proxy-serv01 będzie MASTER dla wirtualnego IP 192.168.2.101 i BACKUP dla 192.168.2.102, a serwer proxy-serv02 będzie MASTER dla wirtualnego IP 192.168.2.102 i BACKUP dla 192.168.2.101.
Jeśli zapora jest aktywowana na serwerze, musisz dodać reguły dopuszczające dla ruchu multiemisji i protokołu vrrp za pomocą iptables:
iptables -A WEJŚCIE -i eth0 -d 224.0.0.0/8 -j AKCEPTUJ
iptables -A WEJŚCIE -p vrrp -i eth0 -j AKCEPTUJ
Aktywujemy startupy i uruchamiamy usługę keepalived na obu serwerach:
systemctl włącz utrzymanie aktywności
systemctl start keepalived
Po uruchomieniu usługi keepalived wirtualne adresy IP zostaną przypisane do interfejsów z pliku konfiguracyjnego. Zobaczmy aktualne adresy IP w interfejsie serwera eth0:
ip a show eth0
Na serwerze proxy-serv01:

Na serwerze proxy-serv02:

Keepalived: monitoruj kondycję aplikacji i interfejsu
Dzięki protokołowi VRRP możliwe jest monitorowanie stanu serwera, na przykład podczas całkowitej fizycznej awarii serwera lub portu sieciowego na serwerze lub przełączniku. Możliwe są jednak inne problematyczne sytuacje:
- błąd w usłudze serwera proxy - klienci, którzy uzyskają adres wirtualny tego serwera, otrzymają komunikat w przeglądarce z błędem informującym, że serwer proxy jest niedostępny;
- odmowa drugiego interfejsu internetowego - klienci, którzy uzyskają adres wirtualny tego serwera, otrzymają komunikat w przeglądarce z błędem informującym, że nie można nawiązać połączenia.
Aby obsłużyć powyższe sytuacje, użyjemy następujących opcji:
- track_interface - monitorowanie stanu interfejsów; ustawia instancję VRRP w stan FAULT, jeśli jeden z wymienionych interfejsów znajduje się w stanie DOWN;
- skrypt_śledzący - monitorowanie za pomocą skryptu, który powinien zwrócić 0, jeśli weryfikacja zakończy się pomyślnie, 1 - jeśli weryfikacja się nie powiedzie.
Zaktualizuj konfigurację, dodaj monitorowanie interfejsu eth1 (domyślnie instancja VRRP sprawdzi interfejs, z którym jest związany, tj. W bieżącej konfiguracji eth0):
track_interface eth1
Dyrektywa skrypt_śledzący uruchamia skrypt z parametrami zdefiniowanymi w bloku vrrp_script, który ma następujący format:
vrrp_script interwał skryptu - częstotliwość skryptu, domyślnie 1 sekundowy spadek - ile razy skrypt zwrócił niezerową wartość, przy której przełącza się na wzrost stanu FAULT - ile razy skrypt zwrócił wartość zerową, przy której wychodził ze stanu limitu czasu FAULT - upłynął limit czasu, aż skrypt zwróci wynik, po czym zwróci wartość niezerową. weight - wartość, o którą priorytet serwera zostanie zmniejszony w przypadku przejścia do stanu FAULT. Wartość domyślna to 0, co oznacza, że serwer przełączy się w stan FAULT po nieudanym wykonaniu skryptu przez liczbę razy określoną przez parametr fall.
Skonfiguruj monitorowanie wydajności Squid. Możesz sprawdzić, czy proces jest aktywny za pomocą polecenia:
squid -k czek
Utwórz vrrp_script, z parametrami częstotliwości wykonywania co 3 sekundy. Ten blok jest zdefiniowany poza blokami. vrrp_instance.
vrrp_script chk_squid_service script "/ usr / sbin / squid -k check" Interwał 3
Dodaj nasz skrypt do monitorowania w obu blokach vrrp_instance:
track_script chk_squid_service
Teraz, jeśli usługa proxy Squid ulegnie awarii, wirtualny adres IP przełączy się na inny serwer.
Możesz dodać dodatkowe działania gdy zmienia się status serwera.
Jeśli Squid jest skonfigurowany do akceptowania połączeń z dowolnego interfejsu, tj. http_port 0.0.0.0 128, wtedy przy zmianie wirtualnego adresu IP nie będzie żadnych problemów, Squid zaakceptuje połączenia pod nowym adresem. Ale jeśli skonfigurowane są określone adresy IP, na przykład:
http_port 192.168.2.101 128 http_port 192.168.2.102 być może 128
wtedy Squid nie będzie wiedział, że w systemie pojawił się nowy adres, w którym należy wysłuchać żądań klientów. Aby poradzić sobie z takimi sytuacjami, gdy musisz wykonać dodatkowe działania podczas zmiany wirtualnego adresu IP, keepalived zawiera możliwość wykonania skryptu, gdy wystąpi zdarzenie, gdy stan serwera zmieni się, na przykład z MASTER na BACKUP lub odwrotnie. Jest to realizowane przez opcję:
powiadom „ścieżkę do pliku wykonywalnego”
Keepalived: testowanie awaryjne
Po skonfigurowaniu wirtualnego adresu IP sprawdzimy poprawność przetwarzania niepowodzenia. Pierwszym testem jest symulacja awarii jednego z serwerów. Odłączamy od sieci wewnętrzny interfejs sieciowy eth0 serwera proxy-serv01, a on przestaje wysyłać pakiety VRRP, a serwer proxy-serv02 musi aktywować wirtualny adres IP 192.168.2.101. Sprawdzimy wynik za pomocą polecenia:
ip a show eth0
Na serwerze proxy-serv01:

Na serwerze proxy-serv02:
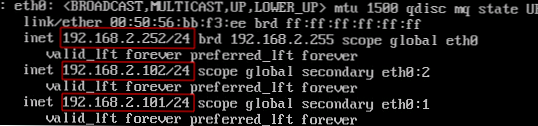
Zgodnie z oczekiwaniami serwer proxy-serv02 aktywował wirtualny adres IP 192.168.2.101. Zobaczmy, co wydarzyło się w dziennikach za pomocą polecenia:
cat / var / log / messages | grep -i keepalived
| na serwerze proxy-serv01 | na serwerze proxy-serv02 |
Keepalived_vrrp [xxxxx]: Jądro zgłasza: interfejs eth0 DOWN Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Wprowadzanie FAULT STATE Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) usuwanie adresów VIP. Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Teraz w stanie BŁĄD | Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Przejście do MASTER STATE |
| Keepalived odbiera sygnał, że interfejs eth0 jest w stanie DOWN i ustawia instancję VRRP proxy_ip1 w stan FAULT, uwalniając wirtualne adresy IP. | Keepalived ustawia instancję VRRP proxy_ip1 w stanie MASTER, aktywuje adres 192.168.2.101 na eth0 i wysyła darmowy ARP. |


I sprawdzimy, czy po podłączeniu interfejsu eth0 na serwerze proxy-serv01 do sieci wirtualny adres IP 192.168.2.101 przełączy się z powrotem.
| na serwerze proxy-serv01 | na serwerze proxy-serv02 |
Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) wymusza nowe wybory MASTER Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Przejście do MASTER STATE Keepalived_vrrp [Keepback] VIP-y Keepalived_vrrp [xxxxx]: Wysyłanie darmowego ARP na eth0 dla 192.168.2.101 | Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Otrzymano reklamę o wyższym priorytecie 255, nasza 100 Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Wprowadzanie stanu zapasowego Keepalived_vrrp [xxxxx]: VRRP__string). |
| Keepalived otrzymuje sygnał do przywrócenia interfejsu eth0 i rozpoczyna nowe wybory MASTER dla instancji VRRP proxy_ip1. Po przejściu do stanu MASTER aktywuje adres 192.168.2.101 na interfejsie eth0 i wysyła darmowy ARP. | Keepalived odbiera pakiet o wysokim priorytecie dla instancji VRRP proxy_ip1 i ustawia proxy_ip1 w stan BACKUP i zwalnia wirtualne adresy IP. |
Drugim testem jest symulacja awarii zewnętrznego interfejsu sieciowego, w tym celu odłączamy zewnętrzny interfejs sieciowy eth1 serwera proxy-serv01 od sieci. Wynik kontroli sprawdzimy przy pomocy logów.
| na serwerze proxy-serv01 | na serwerze proxy-serv02 |
Keepalived_vrrp [xxxxx]: Jądro zgłasza: interfejs eth1 DOWN Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Wprowadzanie FAULT STATE Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) usuwanie protokołu VIP. Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Teraz w stanie BŁĄD | Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Przejście do MASTER STATE Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Wprowadzanie MASTER STATE Keepalived_vrrp [xxxxx]: VRRP_Insts. Protokół proxy Keepalived_vrrp [xxxxx]: Wysyłanie darmowego ARP na eth0 dla 192.168.2.101 |
| Keepalived odbiera sygnał, że interfejs eth1 jest w stanie DOWN i ustawia instancję VRRP proxy_ip1 w stan FAULT, uwalniając wirtualne adresy IP. | Keepalived ustawia instancję VRRP proxy_ip1 w stanie MASTER, aktywuje adres 192.168.2.101 na eth0 i wysyła darmowy ARP. |

Trzecie sprawdzenie jest imitacją awarii usługi proxy Squid, w tym celu ręcznie opuścimy usługę za pomocą polecenia: systemctl stop squid Wynik kontroli sprawdzimy przy pomocy logów.
| na serwerze proxy-serv01 | na serwerze proxy-serv02 |
Keepalived_vrrp [xxxxx]: VRRP_Script (chk_squid_service) nie powiodło się Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Wprowadzanie FAULT STATE Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1). Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Teraz w stanie BŁĄD | Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Przejście do MASTER STATE Keepalived_vrrp [xxxxx]: VRRP_Instance (proxy_ip1) Wprowadzanie MASTER STATE Keepalived_vrrp [xxxxx]: VRRP_Insts. Protokół proxy Keepalived_vrrp [xxxxx]: Wysyłanie darmowego ARP na eth0 dla 192.168.2.101 |
| Skrypt sprawdzania aktywności usługi proxy squid kończy się niepowodzeniem. Keepalived ustawia instancję VRRP proxy_ip1 w stanie FAULT, uwalniając wirtualne adresy IP. | Keepalived ustawia instancję VRRP proxy_ip1 w stanie MASTER, aktywuje adres 192.168.2.101 na eth0 i wysyła darmowy ARP. |
Wszystkie trzy testy zakończyły się pomyślnie, poprawnie skonfigurowano utrzymywanie aktywności. W dalszej części tego artykułu skonfigurujemy klaster HA za pomocą Pacemakera i rozważymy specyfikę każdego z tych narzędzi..
Ostateczny plik konfiguracyjny /etc/keepalived/keepalived.conf dla serwera proxy-serv01:
vrrp_script chk_squid_service skrypt "/ usr / sbin / squid -k check" interwał 3 vrrp_instance proxy_ip1 stan Interfejs MASTER eth0 virtual_router_id 1 priorytet 255 virtual_ipaddress 192.168.2.101/24 dev eth0 etykieta eth0: 1 interfejs track_interface eth1 track_interface interfejs eth1 track_interface interfejs eth1 vrrp_instance proxy_ip2 stan BACKUP interfejs eth0 virtual_router_id 2 priorytet 100 virtual_ipaddress 192.168.2.102/24 dev eth0 etykieta eth0: 2 interfejs Track_script eth1 skrypt_script chk_squid_service
Ostateczny plik konfiguracyjny /etc/keepalived/keepalived.conf dla serwera proxy-serv02:
vrrp_script chk_squid_service skrypt "/ usr / sbin / squid -k check" interwał 3 vrrp_instance proxy_ip1 stan BACKUP interfejs eth0 virtual_router_id 1 priorytet 100 virtual_ipaddress 192.168.2.101/24 dev eth0 etykieta eth0: 1 interfejs_ track_face eth1 track_interface eth1 track_interface eth1 track_interface eth1 track_interface eth1 track_interface eth1 track_interface eth1 track_interface eth1 track_interface eth1 track_interface eth1 track_interface eth1 track_interface eth1 track_interface eth1 track_interface eth1 vrrp_instance proxy_ip2 stan Interfejs MASTER eth0 virtual_router_id 2 priorytet 255 virtual_ipaddress 192.168.2.102/24 dev eth0 etykieta eth0: 2 interfejs_ścieżki eth1 skrypt_synchroniczny chk_squid_service


{kind=link}